background
Partial derivatives and gradient
Hessian
Suppose : is a function taking as input a vector and outputting a scalar ; if all second partial derivatives of exist and are continuous over the domain of the function, then the Hessian matrix of is a square matrix, usually defined and arranged as follows:
use single equation: In case above: so,
Chain rule
Linear regression
Gradient vector
Let be an d-dimensional vector and a scalar-valued function. the gradient vector of with respect to is:
Hessian matrix
Also Hessian matrix defined as
In offline learning, we have a batch of data . We typically optimize cost function of the form
The corresponding gradient is
we have the quadratic cost
Steepset gradient descent algorithm
One of the simplest optimization algorithms is called gradient descent or steepest descent. This can be written as follows: where indexes steps of the algorithm, is gradient at step , and is called the learning rate or step size.
For least squares
Newton’s algorithm
The most basic second-order optimization algorithm. make a second-order Taylor series approximation of around :
For linear regression
Newton CG algorithm
We can solve the linear system of equations for rather than computing .
SGD(Stochastic gradient descent)
위 수식에서 는 러닝을 위한 term이고 그 뒤의 는 noise term이다.
Online learning with mini-batches
Batch
Online
mini-batch

이 과정에서 train과 test의 error function을 계속해서 관찰해야 한다.
만약 train의 error는 줄어드는데 test의 error는 증가할 경우 오버피팅이 발생한 경우이므로 Early stopping을 해주면 된다.
Downpour
수 많은 파라미터들이 서버에 있다고 하자. 우리는 모델의 레플리카를 제작할 것이다. 가장 먼저 레플리카가 로컬 데이터에 접근을 하게 된다. 로컬에는 부분 데이터가 저장되어 있다. 각각의 레플리카 모델은 batch 러닝을 진행한다. 그리고 다시 서버에 파라미터에 올린다. 그것을 서버가 받으면 서버는 정보를 토대로 자신을 업데이트 한다.
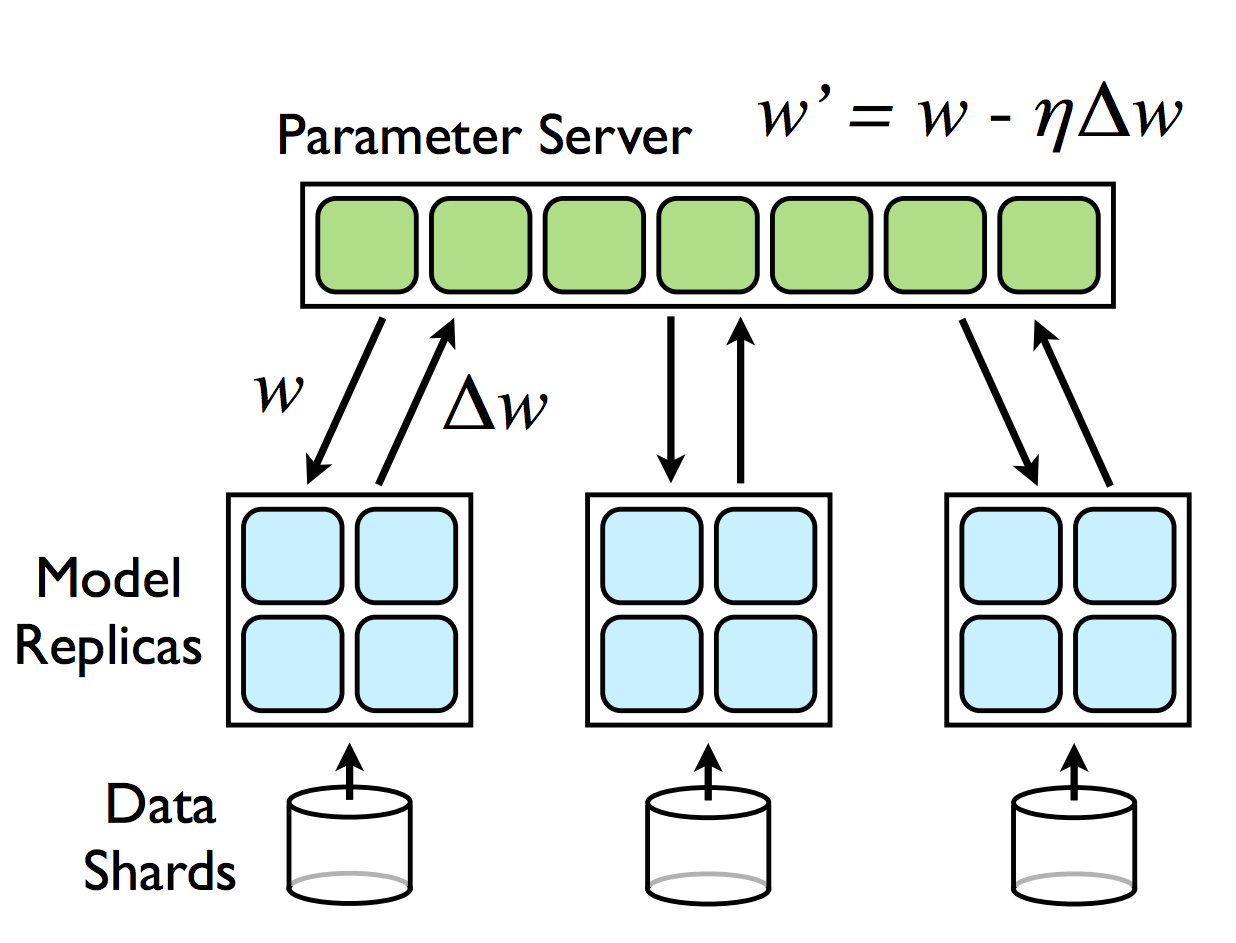
step1: Replica access local data. too much data to load .
step2: compute mini batch.
step3: update gradient to server.
추가적으로 큰 뉴럴 네트워크의 경우 각각을 쪼개서 로컬 업데이트 하도록 만들 수 있다.각각이 커뮤니케이션을 가지도록 한다면 충분히 가능하다.
Polyak averaging
Pick average when decent next step.
It will helpful when the is big so that the location of is vibrating.
Momentum
For three-dimensional planes shaped like valleys, running takes a long time.
This will not decent constant speed.
Adagrad
Looking at the history of how much samples change the loss.
Rare features are able to get a larger update for the parameters.
This technique is used like in text data.