McCulloch-Pitts model

시냅스는 활동전위를 다른 시냅스로 부터 받아서 다른 시냅스로 보내준다. 이와 같은 방식으로 모델을 만든다. 여러개의 파라미터를 받고 이들을 모두 더한 뒤에 function을 통하게 한다. 이 function은 threshold를 정해 이보다 높다면 1 낮다면 0으로 변환시킨다. 일반적인 경우에는 Sigmoid function을 사용한다.
Sigmoid function
sigm() refers to the sigmoid function, also known as the logistic or logit function:
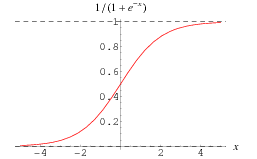
sigmoid 함수의 결과 :
이때의 output
Linear separating hyper-plane
결과가 0.5가 될 때가 바로 경계면을 나타낸다.
즉, sigmoid에서는 가 0이 되는 지점이다.
이 지점을 discriminant라고 한다.

Entropy
entropy 는 uncertainty를 위한 measure이며 random variable 로 나타내어 진다.
Example of Bernoulli
For a Bernoulli variable , the entropy is:
Logistic regression
In logistic regression prediction results are binary. The logistic regression model specifies the probability of a binary output given the input as follows:
Cross-Entropy
Gradient and Hessian
The gradient and Hessian of the negative loglikelihood(NLL), are given by:
where
One can show the is positive definite : hence the NLL is convex and has a unique global minimum.
Iteratively reweighted least squares (IRLS)
For binary logistic regression, recall that the gradient and Hessian of the negative log-likelihood are given by
The Newton update at iteration for this models is as follows (using ,since the Hessian is exact ):
Softmax formulation
의 인풋이 파라미터 와 곱해지고 그 것들을 모두 더한 벡터 가 나오고 여기에서 sigmoid fucntion을 통해서 결과를 구하게 된다. 이것이 앞에서 했던 McCulloch-Pitts 모델이다.
이제는 파라미터의 갯수가 증가할 것이다. 단순히 생각한다면 개의 model을 연결해 놓은 것이다. 각각의 model의 아웃풋을 softmax 함수에 넣게 되면 결과가 나오게 될 것이다.
모델이 2개인 경우를 생각해보자. 모델이 2개인 경우 인풋 에 대해서
2배가 된 파라미터와 각각 곱해져 각각의 모델의 아웃풋으로 나오게 된다 결과적으로 가 될 것이고 두 값을 더하면 1이 될 것이다.
이때 각각의 값은
이는 class 1과 class 2중에서 어떠한 것이 더 결과 값에 적합한지를 판단하는 방식이 될 수 있다.
Likelihood function
INDICATOR:
Then:
when
Negative log-likelihood
Neural network representation of loss

위의 과정을 여러개의 레이어로 생각해 볼 수도 있다.